Controls for Apheris Stats🔗
Apheris Stats is the model for (federated) statistics maintained by the Apheris team. It includes a powerful set of statistical functions and function groups.
For the Apheris Stats model you can define
- Permissions: statistical functions or function groups you want to allow
- Privacy controls: privacy-enhancing algorithms you want enforced
Permissions🔗
The Apheris Stats model provides a broad range of statistical functions suitable for simple statistics and advanced data science.
You can choose to allow all functions on your dataset or select specific functions or function groups to be permitted. To allow a function, just check the box next to it.

Available permissions🔗
- All functions: select to enable all available statistical functions
- Only specific functions: select to enable only specific functions, as described below
-
Functions: individual functions run on the Compute Gateway and return a single value per Gateway or dataset respectively :
- Confidence intervals: probability that a population parameter falls between a set of values around a mean. Most often constructed using a 95% confidence level
- Count value: data type that takes only counting non-negative integer values where the values are obtained by counting rather than be ranking
- Count group by: group by columns to compute the count
- Count null: compute null values in columns
- Histogram: graphically display data using bars to view the center, spread and shape of data
- IQR: (Interquartile Range) describes the spread of the middle half (mean) of a distribution
- Max: largest value in a dataset
- Mean: average of given data values determined by dividing the sum of the values by total number of the values
- Median: central value of a distribution where half the points are less than or equal to it and half are greater than or equal to it
- Median with quartiles: values which divide the distribution where a given proportion of observations are below the quartile
- Min: smallest value in a dataset
- Shape: describes the distribution (or pattern) of data within a dataset and can be symmetrical or asymmetrical
- Squared errors by column: average of the sums of the squares of each difference between estimated and true value and is always positive
- Sum column: compute the total of a column
- Aggregation functions: aggregation functions use the values computed with individual functions from the Gateway or dataset and aggregate these securely on the Orchestrator. Available aggregation functions are:
- Confidence intervals aggregation: method that simply takes the unweighted average of the midpoints of each interval
- IQR aggregation: aggregation function for the interquartile range
- Max aggregation: maximum value in a group of values
- Mean aggregation: mean over multiple datasets. It returns the overall mean, accounting for the length of each dataset
- Median with quartiles aggregation: aggregation of first quartile, median and third quartile and which must be used in combination with median with quartiles column.
- Min aggregation: minimum value in a group of values
- Sum aggregation: sum over multiple datasets. It returns the overall sum
- Sum: sum of values in a group of values
Function Groups🔗
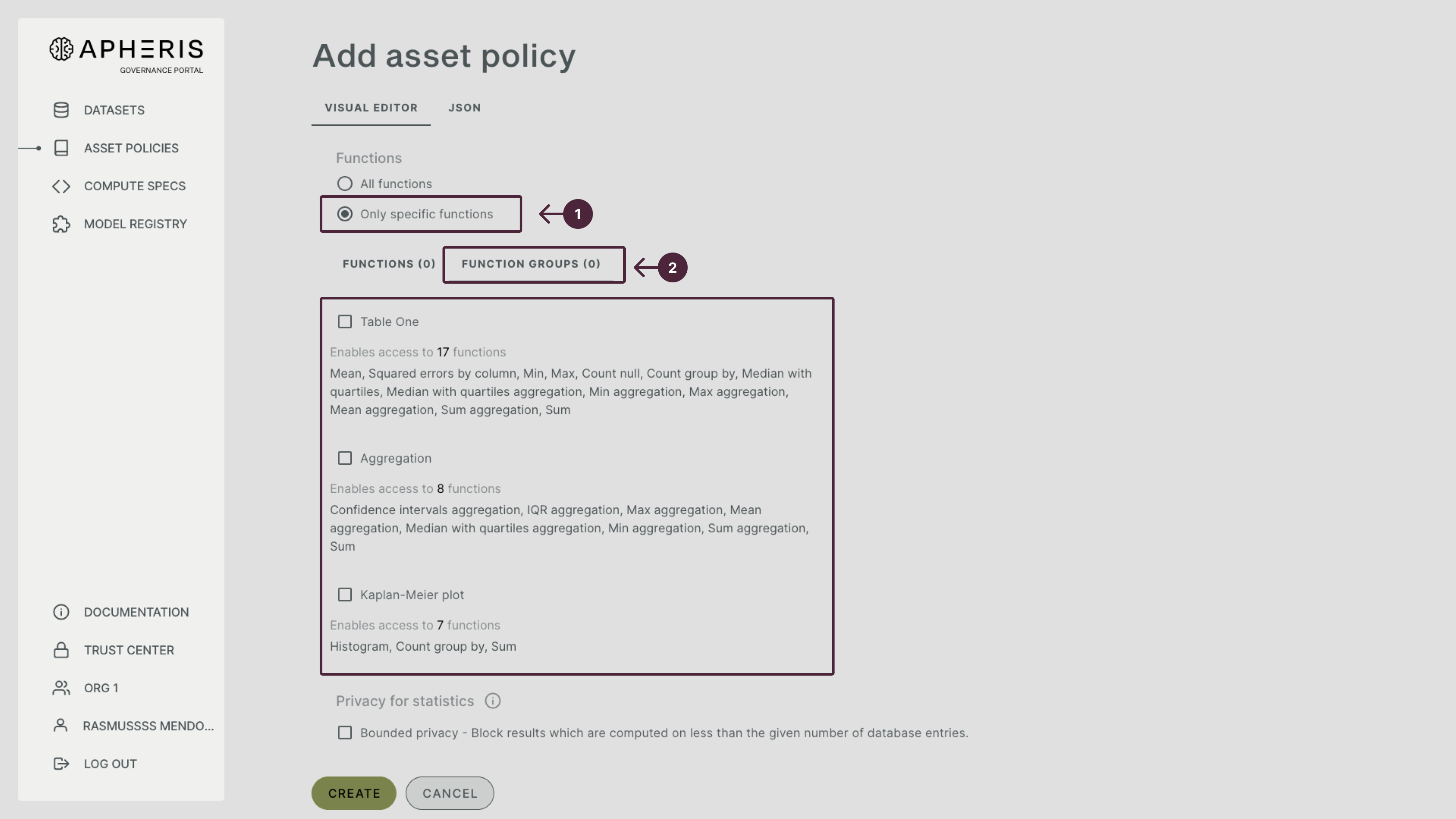
- Function Groups: select from a curated collection of functions:
- Table One: uses the following collection of functions, which are described above (Note: Sankey plot is enabled when this option is selected): Mean, Squared errors by column, Min, Max, Count null, Count group by, Median with quantities, Median with quantities aggregation, Min aggregation, Max aggregation, Mean aggregation, Sum
- Aggregation: uses the following collection of aggregation functions, which are described above: Confidence intervals aggregation, IQR aggregation, Max aggregation, Mean aggregation, Median with quantities aggregation, Min aggregation, Sum aggregation, Sum
- Survival Analysis: select type of diagram for determining the time predicted for an event to occur:
- Kaplan-Meier plot: type of diagram to estimate survival from lifetime data (enables Histogram, Count group by and Sum)
- Sankey plot: type of diagram that shows the flow from one set of values where the width of arrows is proportional to the flow rate (enables Count by group and Sum)
Privacy controls in Apheris Stats🔗
There are three main privacy controls for the Apheris Stats model:
-
Bounded Privacy - Prevent that query results are returned for a small numbers of rows or individuals based on a defined threshold. If such small numbers would be returned by queries, then there is a risk that those individuals might be identified from the query result.
-
Noise Privacy - Add a small, intentional error margin to all computation results which is insignificant when aggregated statistics are used but which also reduces the risk that individuals might be identified from the query result.
-
Rounded Privacy - Round the final result of the computation to a Data Custodian-defined number of significant digits to avoid the abuse of less significant digits for extraction of private information.
These controls protect privacy and assist in ensuring regulatory compliance. For your protection, the Apheris product applies those privacy controls automatically when selected in an asset policy.
Asset policies are enforced both when simulating on dummy data and running on real data to ensure a consistent user experience. That means that Bounded Privacy also applies to simulating on dummy data. When configuring Bounded Privacy, please make sure to add dummy data with a size equal or greater than the privacy bound to allow for testing federated computations.
Bounded privacy🔗
Bounded means that there is a minimum number of individual records that must be present in a dataset after pre-processing for a query to return a result. This means that any query that would be computed on a dataset containing less entries than a certain threshold would not be computed and thus no results are returned for such a query. For a federated computation across multiple datasets, all datasets with specified Bounded Privacy settings need to fulfill the privacy requirements individually for the results to be returned.
The check for the minimum number of entries is applied after pre-processing. This ensures that the original data size is not chosen for this check but the actual (potentially much smaller) filtered data before the statistics operation (count, mean, etc.) is performed on this filtered data. Consequently, these bounds are applied to any (temporary) subset of the data (as a result of pre-processing) that is created in the process of computing the query.
Configuring Bounded Privacy🔗
A data custodian can specify Bounded Privacy settings in asset policies. For a given dataset, data custodians can define the minimum number of entries that must be present in any dataset for a query to return a result.

Handling bounded privacy violations🔗
In many cases single outliers in a dataset can lead to bounded privacy violations when a stratifier is specified or a histogram is being computed. To still enable statistical computations and preventing statistical disclosure at the same time, we offer several handling methods. The handling method is specified as a function argument (handle_outliers) of the statistical computations.
-
FILTER: If this method is specified for a computation, all groups (or histogram bins) that violate the privacy bound are filtered out. The other groups are still returned.
-
FILTER_DATASET: If this method is specified, the entire dataset is removed from the computation. That means the computation for this dataset will return an empty set, and only the results of the other datasets are aggregated in the central orchestrator.
-
ROUND: This handling method is only supported for count computations and histograms. If this method is selected all groups or histogram bins will be rounded to the minimum entry specified as privacy bound if they contain at least
0.5*min_entriesdata points and to 0 else-wise. -
RAISE: This method is the default behavior and will raise a
PrivacyExceptionas soon as bounded privacy is violated for at least one group in one dataset. No results are being returned.
If a specific handling method is allowed on a dataset or not must be configured by the data custodian in the asset policy of a dataset.
Noise privacy🔗
Noise defends against a category of attacks that work as follows: an attacker systematically runs multiple queries that slightly differ from each other and then observes the changes in the query results. With this information, the attacker can compare the query results with each other and then derive sensitive information over a small subset of the data by analyzing the differences between the query results.
The Apheris Computational Governance Solution addresses such attacks by adding noise to the query result. This is done by modifying every result value by a small but unpredictable amount of noise.
Even though adding noise deliberately increases inaccuracy of a query result, this noise is too small to be significant when using aggregated statistics. Adding noise will however impact queries where the result might reveal sensitive information about individuals, whether this is intentional or accidental.
Configuring Noise privacy🔗
Noise Privacy will only work for numerical results and block queries that have other result types. All functions within the Apheris Stats model are compatible with Noise Privacy.
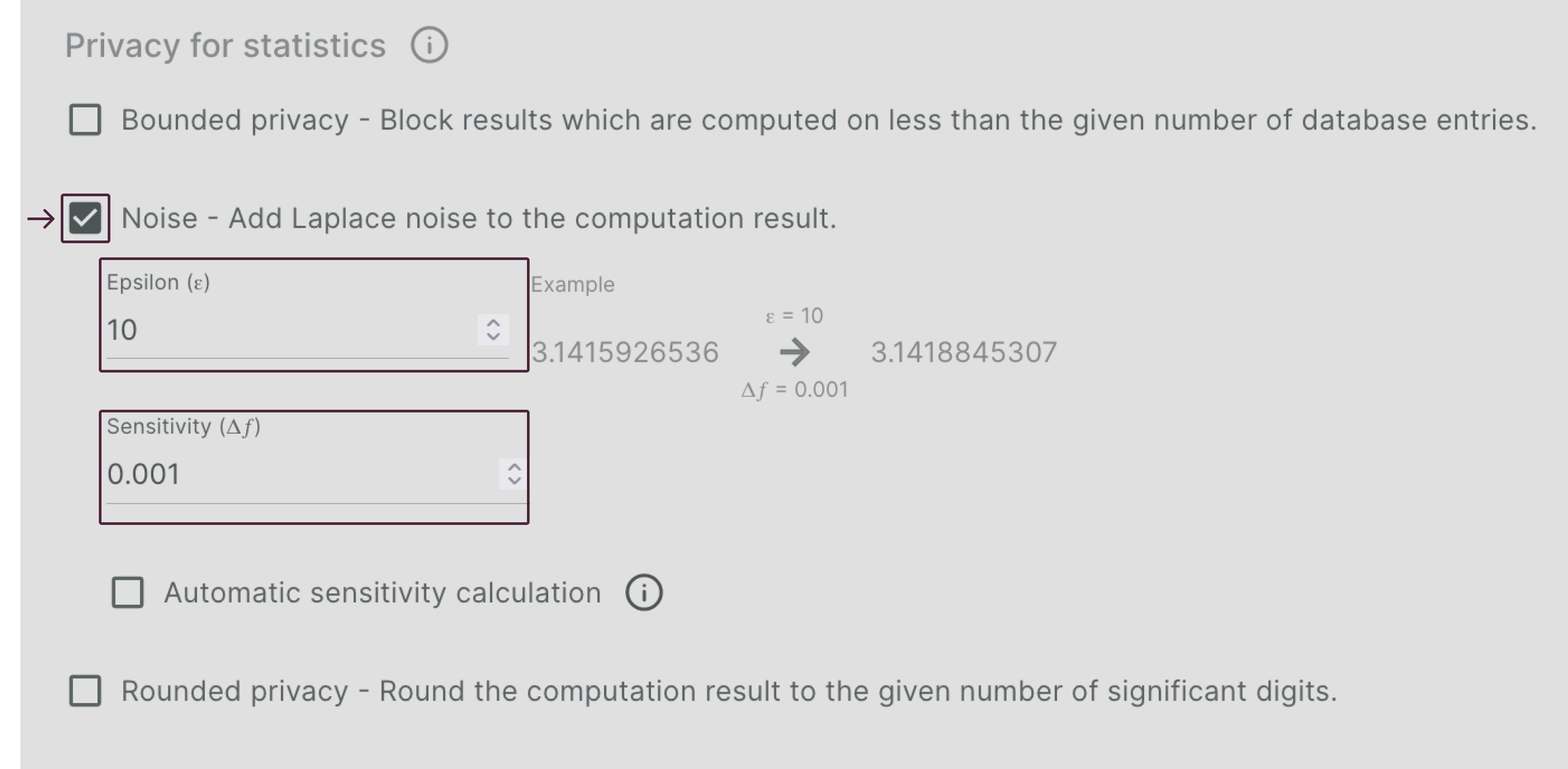
The amount of noise applied to the dataset is determined by the function numpy.random.laplace(loc=0.0, scale=(<sensitivity> / <epsilon>)). If the sensitivity value is set to None, or the "automatic sensitivity calculations" check box is selected, the Apheris platform will attempt to automatically set this value for supported query types. Supported queries for automatic sensitivity calculation are currently:
count_group_by
count_column_value
count_null
histogram_continuous
mean_column
Rounded privacy🔗
By applying rounding to the query results before they are returned to the user, the precision of the query result is influenced. Returning rounded numbers makes it harder for an attacker to infer insights by inspecting the actual precise computation results (for example, counts).
An organization can specify rounding settings in the asset policy. For a given dataset, they can define the significant digits to which a numerical results should be rounded. Note that this only works for numerical results.
Configuring Rounded Privacy🔗
To configure Rounded Privacy, the number of “significant digits” to use has to be defined.
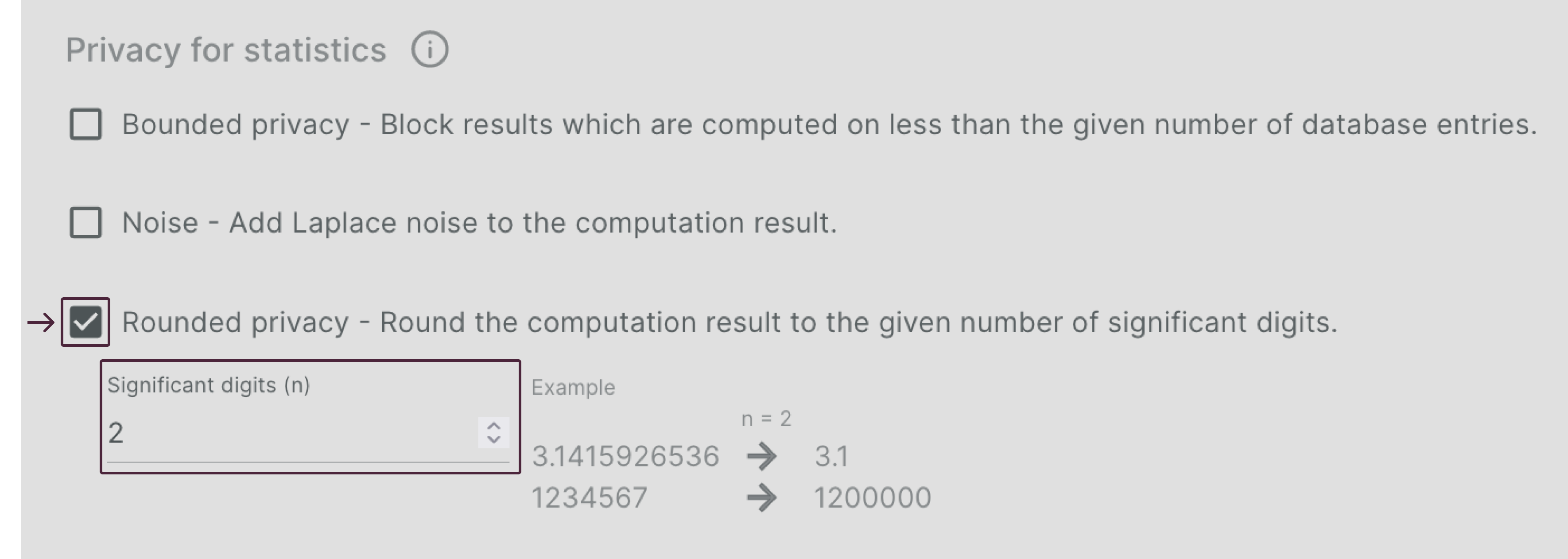
Let’s assume we have a dataset on which a count query is run and without a privacy control this query would return 2.062. If Rounded Privacy with n=2 for the significant digits is defined, then the returned result would not be 2.062 but 2.100. If n=3 would be specified for the significant digits, it would return 2.060.
All functions within the Apheris Stats model are compatible with Rounded Privacy.